Does llms.txt Work in 2026? What Real Data Says About AI Crawler Optimization
Does llms.txt actually help AI visibility? Real server log data, ML studies, and crawler experiments reveal what drives AI citations vs. what's just hype.
TL;DR
Does llms.txt work? Analysis of 400 million server requests showed AI systems entirely ignored llms.txt files. A randomized controlled trial found serving Markdown to bots provides no statistically significant increase in citations. AI crawlers fetch 1,241 pages for every single citation they generate. Citation frequency is determined by content authority, not file formats or technical flags.
When evaluating whether "does llms.txt work," the answer from real server data is clear: AI systems fetch thousands of pages for every single citation they send back. Brands hope adding an llms.txt file or serving Markdown will finally make their content visible to ChatGPT and Claude. The reality found in server logs tells a different story.
Does llms.txt Work: What It Is and What It Was Designed to Do
llms.txt is a Markdown file placed at a website's root to signal important pages to AI systems, similar to robots.txt but targeting large language models.
To understand does llms.txt work, we start with what it is. Jeremy Howard created the concept in September 2024 as a proposed standard, not an official specification. The idea: webmasters place curated, structured site content at /llms.txt so large language models can comprehend a site at inference time. A robots.txt file tells crawlers what to skip. An llms.txt file tells them exactly what to read.
Adoption grew quickly. Over 844,000 sites implemented the file by October 2025. But this number is largely inflated. Mintlify automatically rolled the feature out to all its hosted documentation sites in November 2024. Anthropic, Cursor, Vercel, Stripe, and Shopify received the file overnight without manual intervention.
No major AI platform has officially confirmed they use this file for ranking or citation logic. Google explicitly rejected the protocol. Gary Illyes stated in June 2025 that Google does not support the file and has no plans to do so.
Does llms.txt Work? What AI Crawlers Actually Read
See where you rank across LLM platforms.
Enter your domain and we'll scan your citation rate across ChatGPT, Perplexity, and Google AI.
Prefer to talk? Book a free 30-min call
Server logs show AI crawlers almost never read llms.txt files, with the file receiving only 0.001% of total traffic across 400 million requests.
Dries van Ommeslaeghe, creator of Drupal, ran a detailed server log analysis to test crawler behavior. His site receives significant bot traffic, making it a useful proxy for what AI systems actually do. He offered an llms.txt file and measured who read it. The results: just 52 requests per month out of 400 million total. If those 400 million requests filled a stadium, the llms.txt traffic would be one person.
Those 52 requests did not come from AI bots. They all originated from SEO audit crawlers operated by Semrush and Ahrefs (tools that check technical health dashboards, not AI systems building citation indexes). Website owners see these hits and assume OpenAI is reading their content. It is an SEO tool checking a box.
SE Ranking validated this through machine learning. They built an XGBoost model to predict citation frequency across 300,000 domains. Removing the llms.txt variable actually improved prediction accuracy. The file adds noise to AI citation patterns, not signal.
GPTBot has been observed crawling these files on some sites. Google indexed up to 60,000 llms.txt files by late 2025, then added and removed the file from its own documentation portal (suggesting active internal testing). The data is genuinely mixed at the edges, but the dominant finding is non-use.
| Platform | Official Position | Crawling Behavior |
|---|---|---|
| Explicitly rejected (Illyes, June 2025) | Indexes files but engineers deny using them | |
| OpenAI | No confirmation; recommends robots.txt instead | GPTBot occasionally crawls; inconsistent |
| Anthropic | Endorses the spec in Claude docs | ClaudeBot: no confirmed usage |
| Perplexity | Adopted on own site | No confirmation they read others' files |
Does Serving Markdown Improve AI Crawler Access?
Randomized testing across 381 pages found no statistically significant benefit from serving Markdown versus HTML to AI crawlers.
A three-week randomized controlled experiment found Markdown pages received roughly 16 percent more bot visits than HTML. Statistical tests confirmed this difference was consistent with random noise.
Profound ran the most rigorous test available: 381 pages across 6 websites, January 19 to February 8, 2026. Pages were split evenly between HTML control and Markdown treatment groups. The experiment was powered to detect 40 percent or larger effects. As the researchers noted: if Markdown had a real impact, they would have caught it.
Markdown pages received approximately one additional median bot visit over three weeks. The 16 percent average difference failed every statistical significance test.
Van Ommeslaeghe's experience aligned. Offering Markdown did not reduce total bot traffic. Traffic increased by 7 percent because bots fetched both formats rather than choosing one. AI crawlers are not format-selective.
| Bot | Total Fetches | Markdown % |
|---|---|---|
| Amazonbot | 16,872 | 10.9% |
| ChatGPT-User | 13,864 | 0.1% |
| Meta AI | 9,011 | 5.4% |
| ClaudeBot | 7,144 | 2.1% |
ChatGPT-User fetched Markdown just 0.1 percent of the time across nearly 14,000 total requests.
There is a legitimate academic counterpoint. The HtmlRAG paper found clean HTML outperformed Markdown on QA benchmarks (ASQA Hit@1: HTML 68.50 vs. Markdown ~56.00). HTML preserves semantic structure (headers, lists, tables) that flat Markdown strips away, giving models richer context for complex queries. This matters for RAG system design, but the empirical crawler data shows bots are not selecting based on format anyway.
What Does a 1,241:1 Crawl-to-Citation Ratio Actually Mean?
AI systems fetch 1,241 pages for every single citation they send back, proving the bottleneck is content selection criteria, not access or file format.
Van Ommeslaeghe recorded 1,241 pages crawled per single citation received from AI systems. Google's traditional crawl-to-referral ratio sits between 3:1 and 30:1. AI systems operate as extractive infrastructure. They are not reciprocal by design.

Cloudflare data confirms this: AI bot traffic grew 18 percent between May 2024 and May 2025. Referral traffic from AI systems remains marginal for most sites despite the crawling surge. Understanding how AI models read websites helps clarify why. The fetch-to-cite gap has nothing to do with access.
Accessibility is not the constraint. AI systems can already reach your content. Format signals do not gate citation decisions. What gates them is whether the model judges the content as authoritative, accurate, and useful for a specific query.
Ahrefs found only 12 percent of URLs cited by ChatGPT, Perplexity, and Copilot rank in Google's top 10 for the same query. AI citations diverge from traditional SEO rankings. The technical SEO playbook does not transfer.
What Actually Drives AI Citations?
Content authority signals like cited sources, expert quotes, and brand search volume drive AI visibility far more than technical file formats.
AI citations are driven by content authority signals: cited sources within the article, brand search volume, structured data, and semantic completeness. Not file formats or technical flags.
Content quality signals show the strongest evidence. The Digital Bloom AI Visibility Report analyzed AI citation patterns at scale:
- Adding statistics to content: +22% AI visibility
- Including expert quotes: +37% AI visibility
- Citing sources within your content: +115% visibility lift at position five
These are pure content-quality signals. Zero technical implementation required.
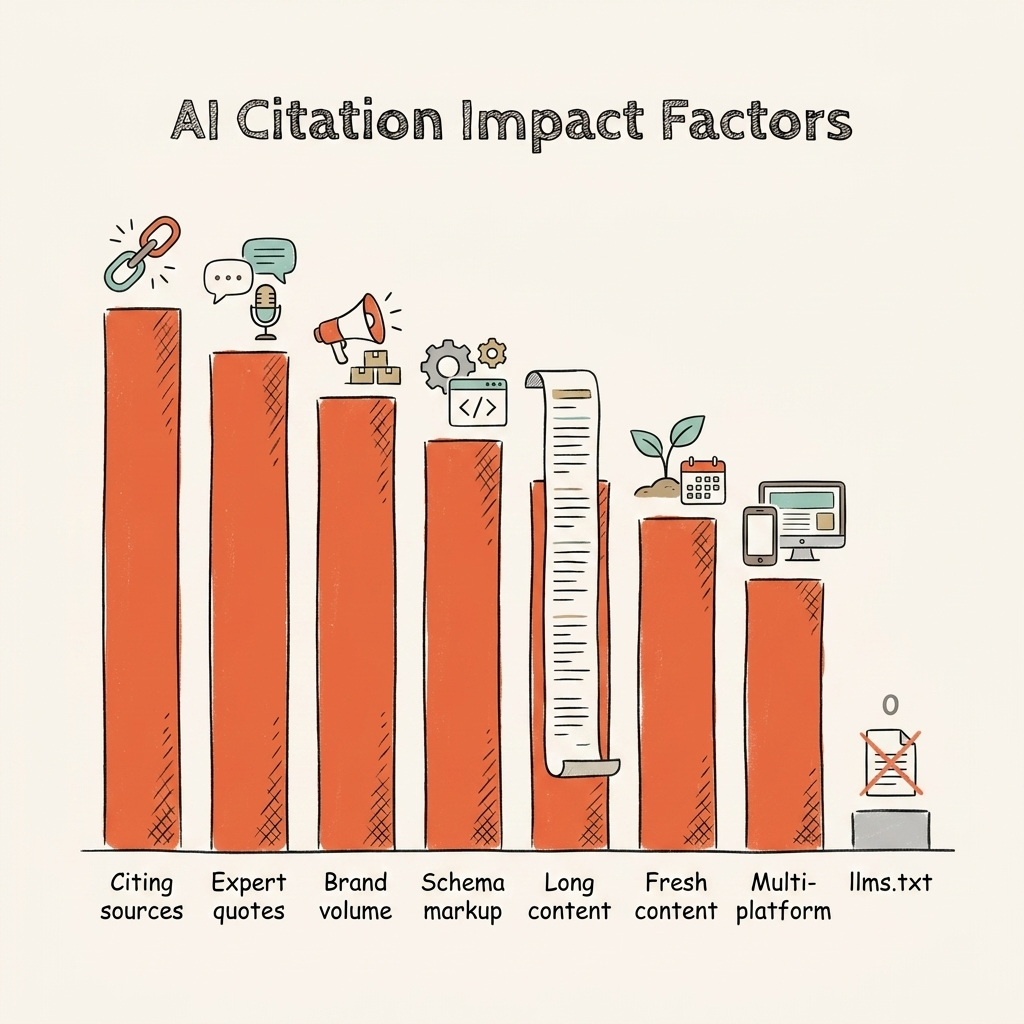
Brand authority is the strongest predictor. Brand search volume shows an r=0.334 correlation with AI citations (stronger than backlink counts). SE Ranking found sites with over 32,000 referring domains are 3.5 times more likely to be cited by ChatGPT than sites with under 200. Building a recognizable brand is what drives AI trust.
Structured data still matters. Pages with well-implemented schema markup see 30–40 percent higher visibility in AI answers. Schema markup for AI visibility gives models semantic certainty about your content's meaning and relationships.
Content depth and freshness both affect selection. Articles over 2,900 words average 5.1 AI citations versus 3.2 for articles under 800 words. Content updated in the past three months averages 6 citations versus 3.6 for outdated pages. Address the content quality gap in AI search by prioritizing depth and recency over technical optimization.
E-E-A-T signals carry real weight. Third-party review profiles on Trustpilot, G2, or Capterra give domains 3x higher citation chances. Brands cited across four or more platforms are 2.8 times more likely to be cited by ChatGPT. E-E-A-T for AI search across the web is a foundational requirement.
| Signal | Impact on AI Citations | Source |
|---|---|---|
| Citing sources within content | +115% visibility | Digital Bloom |
| Including expert quotes | +37% | Digital Bloom |
| Brand search volume | r=0.334 correlation | Digital Bloom |
| Schema markup | +30–40% in AI answers | GEO research |
| Articles 2,900+ words | 5.1 avg citations vs. 3.2 | SE Ranking |
| Content refreshed < 3 months | 6 avg citations vs. 3.6 | SE Ranking |
| Multi-platform brand presence | 2.8x more likely cited | Digital Bloom |
| llms.txt | No measurable impact | SE Ranking ML study |
Should You Implement llms.txt? The Practical Verdict
Implement llms.txt only if it costs under an hour. It is low-cost insurance, not a strategy, and should not displace work on content authority.
Keep the file active if your CMS automatically generates it. Deprioritize it if it requires custom development. The current return on investment does not justify developer time based on empirical evidence.
Serve Markdown only if you get a genuine secondary benefit (developer documentation sites, existing Markdown pipelines). Do not build a parallel content system purely for bot consumption.
Watch for specific signals that would change this verdict:
- An official statement from OpenAI or Google Search confirming they use
llms.txtin citation decisions - Server log data showing more than 5 percent of AI crawler traffic hitting the file consistently
Invest in citation-worthy content instead. Add statistics, secure expert quotes, and cite external sources within articles. Improve your structured data. Build brand presence on third-party review platforms. Refresh high-potential content regularly. Track your AI citations. You cannot optimize what you do not measure. Start by learning how to measure AI visibility.
Frequently Asked Questions About llms.txt
Answers to the most common questions about llms.txt, AI crawler behavior, Markdown formatting, and what actually drives AI citations.
Does Google use llms.txt?
Google engineers publicly rejected the standard in June 2025, stating it has no plans to support it, despite Google indexing tens of thousands of these files globally.
Does ChatGPT read llms.txt files?
GPTBot occasionally crawls llms.txt files, but OpenAI has not confirmed it uses the files in retrieval or ranking decisions. OpenAI's official guidance still points brands to robots.txt.
Will serving Markdown help my site rank in AI search?
Controlled data shows no statistically significant citation benefit from Markdown. Bots primarily fetch HTML, and Markdown fetches represent under 11 percent of most AI crawlers' total requests.
What is the crawl-to-citation ratio for AI systems?
Analysis of one high-traffic site found AI systems fetched 1,241 pages for every single citation they sent, revealing the bottleneck is content selection criteria, not access or file format.
How do I actually improve my AI visibility?
The highest-impact signals are citing external sources within content, including expert quotes, maintaining brand presence on review platforms, and publishing fresh, in-depth content. Track actual citation movement to know what is working.
Conclusion
File formats do not drive AI citations. Content authority does.
Technical optimizations like llms.txt exist and you should implement them if they cost nothing. But the server data is unambiguous: AI systems are not reading these files at meaningful scale. Markdown formatting does not drive more citations. Bots crawl both formats regardless.
The 1,241:1 crawl-to-citation ratio proves accessibility is not the bottleneck. Authority is. The signals that drive AI citations are the same signals that build deep brand trust: cited sources, expert depth, structured data, and multi-platform presence. Brands spending development time on AI-readable file formats are optimizing the wrong layer entirely.
Audit your last five published articles. Count how many cite external sources inline. Adding two or three cited statistics per article is measurably more impactful than any technical formatting change based on current evidence.
See where your brand appears in AI search
Scan ChatGPT, Perplexity, and Google AI across buyer-intent queries, instantly, no sign-up.
Find out if AI is sending buyers to your competitors.
We audit your AI visibility across ChatGPT, Perplexity, and Google AI –and show you exactly where you rank and what to fix.
“We went from 200 visitors/day to 1,900 visitors/day and 40% of demos are from AI search.”
Sumanyu Sharma · CEO, Hamming.ai
“Cintra helped me go from 3k to 7.5k daily traffic and doubled weekly orders in 1.5 months.”
Russ Coulon · Owner, UV Blocker
“We saw a lift from 3% to 13% visibility in the first 2 weeks, and organic traffic hit its highest ever.”
Ash Metry · Founder, Keywords.am
Related Articles
Organic Traffic Decline 2026: Why It's Dropping and How to Recover
Organic traffic decline 2026 is real. AI Overviews cut clicks 38% on triggered queries. Here's what's causing…
AI Visibility Reporting: What to Track, Who to Tell, and How to Prove ROI
AI visibility reporting requires different metrics and formats than SEO reports. Learn the five core metrics,…
AI Visibility Competitive Analysis: How to Find and Exploit Gaps in 2026
AI visibility competitive analysis across ChatGPT, Perplexity, and 5 other engines. Framework for tracking com…